

The AI landscape is evolving at a breathtaking pace, and Meta's recent announcement of the Llama 4 model family represents a significant leap forward in multimodal AI capabilities [1]. As these powerful models push the boundaries of what's possible, they're also highlighting a critical bottleneck in AI development: high-quality data annotation.
Traditional data annotation methods rely heavily on crowdsourced workers or gig economy participants with limited domain expertise. This approach might have been sufficient for earlier AI systems with simpler requirements, but as models like Llama 4 demonstrate unprecedented capabilities in multimodal understanding, reasoning, and specialized knowledge domains, the annotation quality gap is becoming increasingly apparent.
The Llama 4 model family, released on April 5, 2025, showcases what's possible when AI is built with next-generation approaches. The family includes three remarkable models:
What makes Llama 4 truly revolutionary is its innovative architecture. As an example, Llama 4 Maverick models have 17B active parameters and 400B total parameters. Meta uses alternating dense and mixture-of-experts (MoE) layers for inference efficiency. MoE layers use 128 routed experts and a shared expert. Each token is sent to the shared expert and also to one of the 128 routed experts. As a result, while all parameters are stored in memory, only a subset of the total parameters are activated while serving these models. This improves inference efficiency by lowering model serving costs and latency. Llama 4 Maverick can be run on a single NVIDIA H100 DGX host for easy deployment or with distributed inference for maximum efficiency.
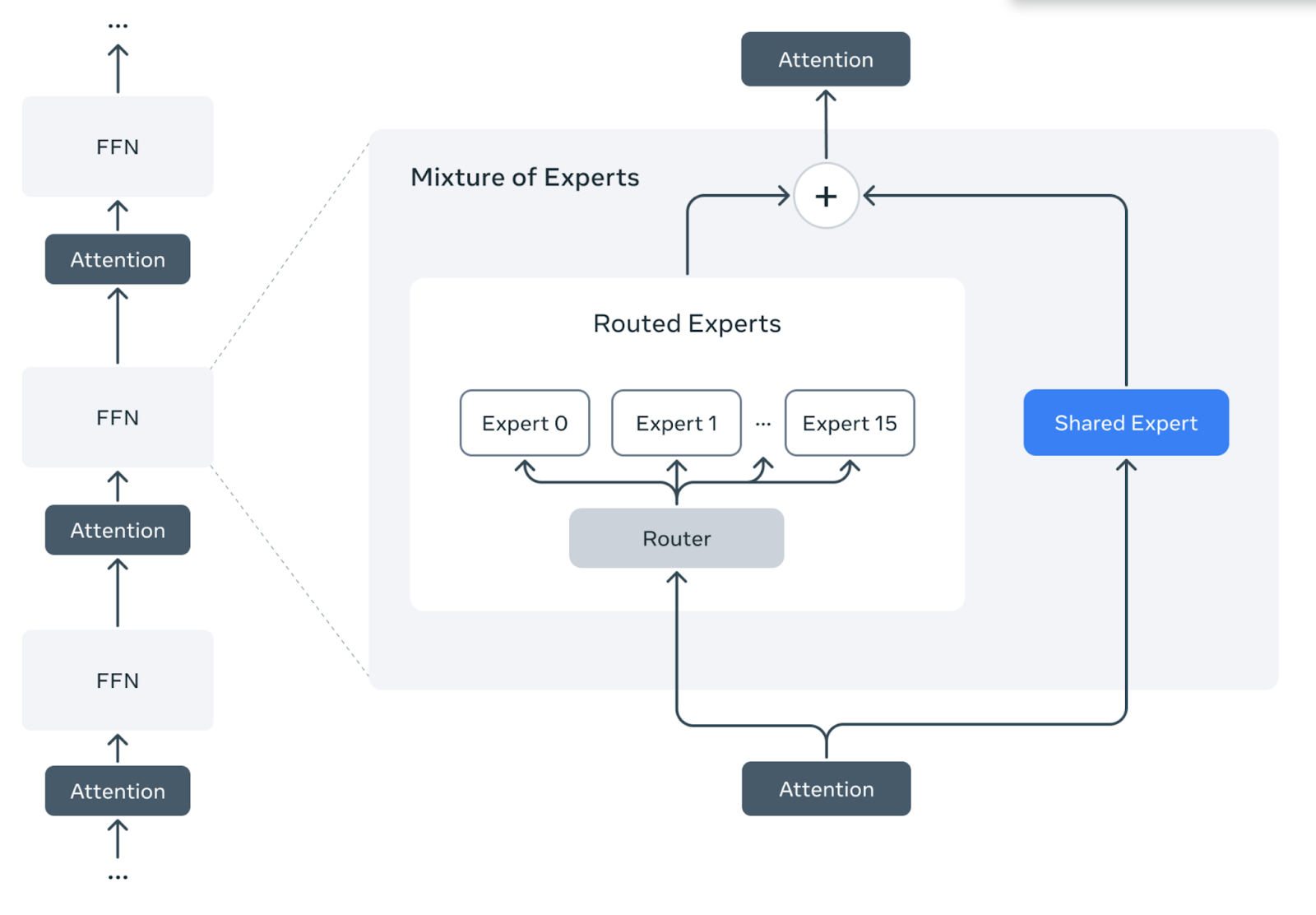
mixture-of-experts (MoE) in LLama 4 architecture, taken from [1]
Llama 4 models are designed with native multimodality, incorporating early fusion to seamlessly integrate text and vision tokens into a unified model backbone. This enables joint pre-training with large amounts of unlabeled text, image, and video data. Additionally, Llama 4 enables open-source fine-tuning efforts by pre-training on 200 languages, including over 100 with over 1 billion tokens each, and overall 10x more multilingual tokens than Llama 3.
These models represent a new era in AI development—one where multimodal capabilities, efficiency, and specialized expertise are seamlessly integrated.
The innovation embodied in Llama 4 highlights precisely why traditional annotation approaches are increasingly problematic:
Just as Meta reimagined what's possible with AI through their innovative Mixture of Experts (MoE) architecture and native multimodality in Llama 4, it's time to reimagine how we annotate data for these advanced models.
This is why novel data pipelines are a perfect complement to innovations like Llama 4. By combining domain expertise, flexible annotation tooling, and next-generation workforce strategies, we need to build annotation capabilities that match the sophistication of today's most advanced AI models.
Unlike traditional data labeling providers, we should not rely on gig workers or crowdsourced annotation. Instead, they build a sustainable, highly-skilled workforce of subject matter experts across STEM domains, including programmers, healthcare professionals, legal experts, mathematicians, and scientists.
When you examine the technical advancements in Llama 4, you can see how domain expert annotation becomes not just beneficial but essential:
1. Enhanced Multimodal Understanding
Llama 4 models are designed with native multimodality, incorporating early fusion to seamlessly integrate text and vision. Domain experts can provide annotations that capture the nuanced relationships between these modalities in ways that generalist annotators cannot, particularly in specialized fields like medical imaging, technical diagrams, or scientific visualizations.
2. Improved Reasoning and Problem-Solving
The Llama 4 Behemoth model achieves 95.0 on the MATH-500 benchmark, demonstrating exceptional mathematical reasoning. Training such capabilities requires annotations from individuals who themselves understand mathematical principles and problem-solving approaches.
3. Specialized Knowledge Domains
Llama 4 models outperform competitors on STEM-focused benchmarks, showing their ability to handle specialized knowledge. Domain expert annotators can provide the high-quality labeled data needed to train these specialized capabilities, ensuring accurate representation of domain-specific concepts and relationships.
4. Long-Context Understanding
Llama 4 Scout offers an unprecedented 10M token context window, enabling multi-document summarization and reasoning over vast codebases. It's pre-trained and post-trained with a 256K context length, which empowers the base model with advanced length generalization capability. The model demonstrates impressive performance in tasks such as "retrieval needle in haystack" for text and code, allowing it to locate and process relevant information buried within massive amounts of data. Annotating for such long-context applications requires annotators who can maintain consistent understanding across extended content—a skill that comes naturally to domain experts regularly working with complex, lengthy technical material.
While Meta has made bold claims about Llama 4's performance on numerous benchmarks, recent events highlight the importance of approaching such claims with healthy skepticism. Earlier this month, Meta found itself in a controversy when it was revealed that the company had used an experimental version of Llama 4 Maverick specifically optimized for "conversationality" to achieve high scores on the LM Arena (also known as Chatbot Arena) benchmark.
When the actual production version of Llama 4 Maverick was added to the leaderboard, it ranked substantially lower, falling below models from OpenAI, Anthropic, and Google that had been released months earlier. This incident underscores the limitations of current benchmarking approaches and the potential for optimization toward specific metrics rather than real-world performance [2]. The following diagram shows the LLama 4- Maverick model's overall performance compared to other models as of April 17, 2025. It is ranked below models such as ChatGPT 4o, Grok-3:

LM Arena [3] itself has faced criticism for several methodological issues [4]:
This doesn't mean Llama 4's capabilities aren't impressive—they certainly are. But it reminds us that the real value of AI systems lies in their practical application and reliable performance in specific domains, not just in headline-grabbing benchmark scores.
The collaboration between advanced models and domain-expert annotation can deliver measurable improvements in AI system performance:
Meta's careful approach to post-training the Llama 4 models offers valuable lessons for data curation. For Llama 4, they revamped their post-training pipeline with a sophisticated approach: lightweight supervised fine-tuning (SFT) > online reinforcement learning (RL) > lightweight direct preference optimization (DPO).
A key insight from their process was that SFT and DPO can over-constrain the model, restricting exploration during the online RL stage and leading to suboptimal accuracy, particularly in reasoning, coding, and math domains. To address this, they removed more than 50% of the data tagged as "easy" by using Llama models as judges and performed lightweight SFT on the remaining harder set. The subsequent multimodal online RL stage, with carefully selected harder prompts, achieved a significant performance boost.
For the massive Llama 4 Behemoth with its 2 trillion parameters, the data curation was even more rigorous—they pruned 95% of the SFT data (compared to 50% for smaller models) to achieve the necessary focus on quality and efficiency. This demonstrates that as models grow in size and complexity, the quality and difficulty of training data becomes exponentially more important than quantity.
Meta also implemented robust safeguards and protections, including Llama Guard (an input/output safety model), Prompt Guard (to detect malicious prompts and prompt injections), and evaluation through CyberSecEval to reduce AI cybersecurity risks. These safety measures are critical as models become more powerful and capable.
Meta's decision to open-source Llama 4 Scout and Llama 4 Maverick reflects their belief that "openness drives innovation and is good for developers, good for Meta, and good for the world." This same philosophy applies to data annotation—more open, collaborative approaches that leverage true domain expertise will drive the next generation of AI advancements.
The combination of cutting-edge models like Llama 4 and expert-driven annotation represents a powerful synergy. As models become more sophisticated, the quality of their training data becomes even more critical to their success.
As AI continues its rapid evolution with models like Llama 4 leading the way, the old annotation paradigm is becoming increasingly obsolete. The future belongs to approaches that match the sophistication of these models with equally sophisticated annotation methodologies.
The Llama 4 story demonstrates two crucial points about the future of AI development:
AI teams need better data. Perle makes that possible through domain expertise-driven annotation that matches the capabilities of today's most advanced models. As we enter this new era of natively multimodal AI innovation, isn't it time your annotation strategy evolved as well?
Contact Perle today to learn how domain expert annotation can help you build better AI models, faster.
[1] https://ai.meta.com/blog/llama-4-multimodal-intelligence/
[3] https://lmarena.ai/?leaderboard

No matter your needs or data complexity, Perle's expert-in-the-loop platform supports data collection, complex labeling, preprocessing, and evaluation-unlocking Perles of wisdom to help you build better AI, faster.